

面试题整理
话说今天又没有成功吊打面试官,记录下
1、RocketMQ是如何保证消息可靠的?保证消息不丢失^1
RocketMQ消息的大致流程过程:
Producer(生产者生产消息) -> Broker(存储消息) -> Consumer(消费消息)
Producer如何保证消息不丢失
- 默认情况下,可以通过同步的方式阻塞式的发送,check SendStatus,状态是OK,表示消息一定成功的投递到了Broker,状态超时或者失败,则会触发默认的2次重试。此方法的发送结果,可能Broker存储成功了,也可能没成功
- 采取事务消息的投递方式,并不能保证消息100%投递成功到了Broker,但是如果消息发送Ack失败的话,此消息会存储在CommitLog当中,但是对ConsumerQueue是不可见的。可以在日志中查看到这条异常的消息,严格意义上来讲,也并没有完全丢失
- RocketMQ支持 日志的索引,如果一条消息发送之后超时,也可以通过查询日志的API,来check是否在Broker存储成功
Broker如何保证消息不丢失
- 消息支持持久化到Commitlog里面,即使宕机后重启,未消费的消息也是可以加载出来的
- Broker自身支持同步刷盘、异步刷盘的策略,可以保证接收到的消息一定存储在本地的内存中
- Broker集群支持 1主N从的策略,支持同步复制和异步复制的方式,同步复制可以保证即使Master 磁盘崩溃,消息仍然不会丢失
Consumer如何保证消息不丢失
- Consumer自身维护一个持久化的offset(对应MessageQueue里面的min offset),标记已经成功消费或者已经成功发回到broker的消息下标
- 如果Consumer消费失败,那么它会把这个消息发回给Broker,发回成功后,再更新自己的offset
- 如果Consumer消费失败,发回给broker时,broker挂掉了,那么Consumer会定时重试这个操作
- 如果Consumer和broker一起挂了,消息也不会丢失,因为consumer 里面的offset是定时持久化的,重启
2、实际业务中的分布式事物的场景如何处理^2
一、两阶段提交(2PC)
-
运行过程
-
协调者询问参与者事务是否执行成功,参与者发回事务执行结果。
-
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
-
-
存在的问题
- 同步阻塞 所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
- 单点问题 协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作。
- 数据不一致 在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
- 太过保守 任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
二、补偿事务(TCC)
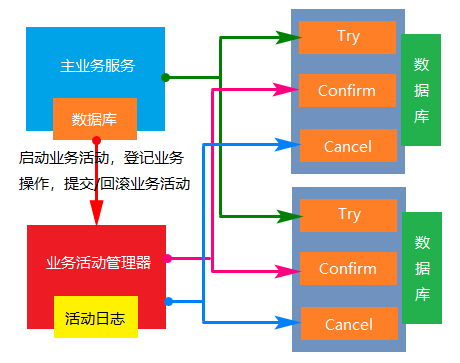
- 实现:一个完整的业务活动由一个主业务服务于若干的从业务服务组成。主业务服务负责发起并完成整个业务活动。从业务服务提供TCC型业务操作。业务活动管理器控制业务活动的一致性,它登记业务活动的操作,并在业务活动提交时确认所有的TCC型操作的Confirm操作,在业务活动取消时调用所有TCC型操作的Cancel操作。
- 成本:实现TCC操作的成本较高,业务活动结束的时候Confirm和Cancel操作的执行成本。业务活动的日志成本。
- 使用范围:强隔离性,严格一致性要求的业务活动。适用于执行时间较短的业务,比如处理账户或者收费等等。
- 特点:不与具体的服务框架耦合,位于业务服务层,而不是资源层,可以灵活的选择业务资源的锁定粒度。TCC里对每个服务资源操作的是本地事务,数据被锁住的时间短,可扩展性好,可以说是为独立部署的SOA服务而设计的。
三、基于可靠消息的最终一致性
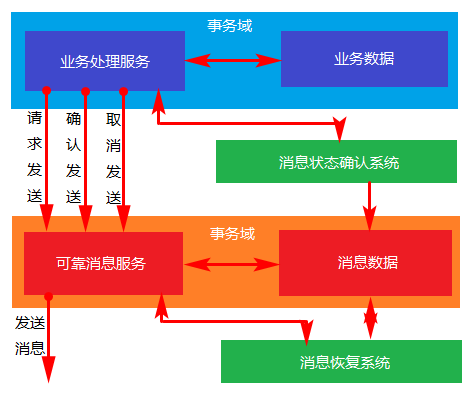
- 实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。
- 消息:业务处理服务在业务事务回滚后,向实时消息服务取消发送。消息发送状态确认系统定期找到未确认发送或者回滚发送的消息,向业务处理服务询问消息状态,业务处理服务根据消息ID或者消息内容确认该消息是否有效。被动方的处理结果不会影响主动方的处理结果,被动方的消息处理操作是幂等操作。
- 成本:可靠的消息系统建设成本,一次消息发送需要两次请求,业务处理服务需要实现消息状态回查接口。
- 优点:消息数据独立存储,独立伸缩,降低业务系统和消息系统之间的耦合。对最终一致性时间敏感度较高,降低业务被动方的实现成本。兼容所有实现JMS标准的MQ中间件,确保业务数据可靠的前提下,实现业务的最终一致性,理想状态下是准实时的一致性。
四、最大努力通知型
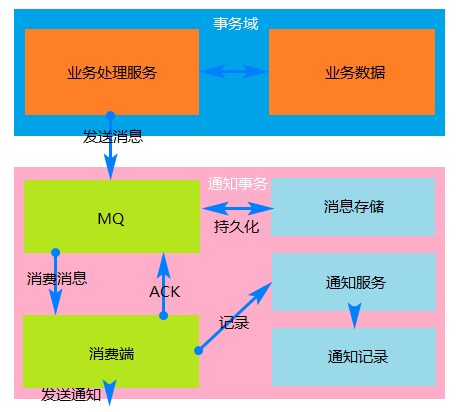
- 实现:业务活动的主动方在完成处理之后向业务活动的被动方发送消息,允许消息丢失。业务活动的被动方根据定时策略,向业务活动的主动方查询,恢复丢失的业务消息。
- 约束:被动方的处理结果不影响主动方的处理结果。
- 成本:业务查询与校对系统的建设成本。
- 使用范围:对业务最终一致性的时间敏感度低。跨企业的业务活动。
- 特点:业务活动的主动方在完成业务处理之后,向业务活动的被动方发送通知消息。主动方可以设置时间阶梯通知规则,在通知失败后按规则重复通知,知道通知N次后不再通知。主动方提供校对查询接口给被动方按需校对查询,用户恢复丢失的业务消息。
- 适用范围:银行通知,商户通知。
3、延时队列是怎么实现的?如何实现延时队列?
一、应用场景
什么是延时队列?顾名思义:首先它要具有队列的特性,再给它附加一个延迟消费队列消息的功能,也就是说可以指定队列中的消息在哪个时间点被消费。
延时队列在项目中的应用还是比较多的,尤其像电商类平台:
- 订单成功后,在30分钟内没有支付,自动取消订单
- 外卖平台发送订餐通知,下单成功后60s给用户推送短信
- 如果订单一直处于某一个未完结状态时,及时处理关单,并退还库存
- 淘宝新建商户一个月内还没上传商品信息,将冻结商铺等
二、实现
-
DelayQueue 延时队列
JDK中提供了一组实现延迟队列的API,位于Java.util.concurrent包下DelayQueueDelayQueue是一个BlockingQueue(无界阻塞)队列,它本质就是封装了一个PriorityQueue(优先队列),PriorityQueue内部使用完全二叉堆(不知道的自行了解哈)来实现队列元素排序,我们在向DelayQueue队列中添加元素时,会给元素一个Delay(延迟时间)作为排序条件,队列中最小的元素会优先放在队首。队列中的元素只有到了Delay时间才允许从队列中取出。队列中可以放基本数据类型或自定义实体类,在存放基本数据类型时,优先队列中元素默认升序排列,自定义实体类就需要我们根据类属性值比较计算了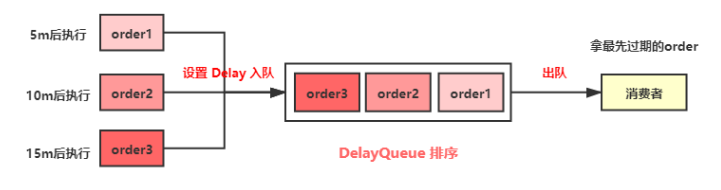
-
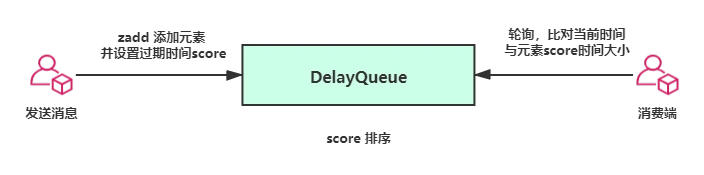
Redis sorted set
利用 Redis 的 sorted set 结构,使用 timeStamp 作为 score,比如你的任务是要延迟5分钟,那么就在当前时间上加5分钟作为 score ,轮询任务每秒只轮询 score 大于当前时间的 key即可,如果任务支持有误差,那么当没有扫描到有效数据的时候可以休眠对应时间再继续轮询
-
RabbitMQ队列
RabbitMQ 有两个特性,一个是 Time-To-Live Extensions,另一个是 Dead Letter Exchanges。
-
Time-To-Live Extensions
RabbitMQ允许我们为消息或者队列设置TTL(time to live),也就是过期时间。TTL表明了一条消息可在队列中存活的最大时间,单位为毫秒。也就是说,当某条消息被设置了TTL或者当某条消息进入了设置了TTL的队列时,这条消息会在经过TTL秒后 “死亡”,成为Dead Letter。如果既配置了消息的TTL,又配置了队列的TTL,那么较小的那个值会被取用。
-
Dead Letter Exchanges
在 RabbitMQ 中,一共有三种消息的 “死亡” 形式:
- 消息被拒绝。通过调用
basic.reject或者basic.nack并且设置的requeue参数为 false; - 消息因为设置了TTL而过期;
- 队列达到最大长度。
- 消息被拒绝。通过调用
DLX同一般的 Exchange 没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。当队列中有 DLX 消息时,RabbitMQ就会自动的将 DLX 消息重新发布到设置的 Exchange 中去,进而被路由到另一个队列,publish 可以监听这个队列中消息做相应的处理。
-
4、如何使用Zuul对某一个IP进行限流^3
在项目中,大部分都会使用到hyrtrix做熔断机制,通过某个预定的阈值来对异常流量进行降级处理,除了做服务降级以外,还可以对服务进行限流,分流,排队等。
当然,zuul也能做到限流策略,最简单的方式就是使用自定义的filter加上限流算法,生产环境中zuul网关肯定是部署的多节点,所以还会借助类似Redis的K/V存储工具。
它提供了多种细粒度策略:
- user:认证用户名或者匿名,针对某个用户进行限流。
- origin:客户机IP,针对请求的客户机IP进行限流。
- url:针对某个特定的url进行限流。
- serviceId:针对某个服务进行限流。
多粒度临时变量存储方式:
- IN_MEMEORY:基于本地内存,底层是ConcurrentHashMap。
- REDIS:基于Redis的K/V存储。
- CONSUL:基于consul的K/V存储。
- JPA:基于数据库。
- BUKET4J:Java编写的基于令牌桶算法的限流库,它有4种模式,JCache、Hazelcast、Apache Ignite、Inifinispan,后面3种支持异步。
配置文件参考:
zuul:
routes:
client-a:
path: /client/**
serviceId: client-a
ratelimit:
#key-prefix: springcloud-book #按粒度拆分的临时变量key前缀
enabled: true #启用开关
repository: IN_MEMORY #key存储类型,默认是IN_MEMORY本地内存,此外还有多种形式
behind-proxy: true #表示代理之后
default-policy: #全局限流策略,可单独细化到服务粒度
limit: 2 #在一个单位时间窗口的请求数量
quota: 1 #在一个单位时间窗口的请求时间限制(秒)
refresh-interval: 3 #单位时间窗口(秒)
type:
- user #可指定用户粒度
- origin #可指定客户端地址粒度
- url #可指定url粒度
上面的配置是说,3秒中内不能有超过2次的接口调用,只需在zuul工程中加入pom依赖,修改配置文件,即可实现效果。
5、Feign有什么好处,是如何实现负载均衡的
Feign是一个声明式的伪Http客户端,它使得写Http客户端变得更简单。 使用Feign,只需要创建一个接口并注解。
Feign是一个HTTP请求调用的轻量级框架,可以以JAVA接口注解的方式调用HTTP请求,而不用像Java中通过封装HTTP请求报文的方式直接调用。Feign通过处理注解,将请求模板化,当实际调用的时候,传入参数,根据参数再应用到请求上,进而转化成真正的请求。
它具有可插拔的注解特性,可使用Feign 注解和JAX-RS注解。Feign支持可插拔的编码器和解码器。
Feign默认集成了Ribbon
- 封装了HTTP调用流程,更适合面向接口化开发
- 代码少,使用简单
- 几乎完全可以从服务提供方的Controller中依靠复制操作,来构建出相应的服务接口客户端,或是通过Swagger生成的API文档来编写出客户端,亦或是通过Swagger的代码生成器来生成客户端绑定(复制粘贴党的福音)
6、Mysql的某个字段存null和空字符串有什么区别?效率和空间上有什么区别
- 空值不占用内存空间,
NULL占用空间 - 在进行
count()统计某列的记录数的时候,如果采用的NULL值,系统会自动忽略掉,但是空值是会进行统计到其中的 - 查找指定列是否为NULL不能使用’=’和’!=’,也不能用'<>’,只能使用 IS NULL IS NOT NULL
部分题目答案引用